VVV (Venice) Token Price & Latest Live Chart
2026-03-09 11:12:16

What is VVV (Venice)?
Venice is an infrastructure platform that combines generative AI services with crypto networks. Its core goal is not to build another brand new frontier model. Its goal is to redefine how AI is accessed and used. The platform delivers text generation, image generation, code generation, and AI character interaction on top of open-source models and distributed compute. Privacy and low-censorship access are built into the product design from the start. That makes Venice closer to a private, programmable, and composable AI inference layer than a standard consumer chatbot. The project was launched by Erik Voorhees and Teana Baker Taylor in May 2024. Its long-term narrative has centered on digital sovereignty, decentralized inference, and the composability of open-source models. Venice is not simply offering an interface for AI conversations. It is trying to pull AI services out of the account systems, content filters, and data retention structures that define centralized platforms, then rebuild them as a capability layer that resembles open internet infrastructure. This allows users and developers to access inference without depending on permission from a single company.
Most mainstream AI platforms keep conversation records, user preferences, account identity, and content safety policies inside centralized servers. That structure may be easier to manage, but it also forces users to trade off convenience, privacy, portability, and freedom of access. Venice takes a different approach. It tries to minimize the amount of data the platform itself needs to hold. Chat history is kept locally. Inference requests are encrypted and routed through proxy mechanisms to external GPU providers. This reduces the risk that sensitive data will accumulate inside a single platform-controlled environment. That design does not mean Venice is fully detached from infrastructure providers, and it does not mean there are no external dependencies anywhere in the stack. What it does mean is that the control over data is distributed differently. Users do not need to accept a fully centralized data relationship just to use AI capabilities. In the crypto market, that design naturally connects with long-standing values such as self-custody, permissionless access, and censorship resistance. That is why Venice fits so easily into the broader Web3 and AI convergence narrative.
Venice represents a model in which AI services are treated as open network resources rather than closed platform features. The main difference between this model and the traditional SaaS AI model is not simply output quality. The bigger difference is how the relationship between the user and the system is defined. Conventional platforms emphasize accounts, permissions, platform rules, and server-side data retention. Venice places more weight on local data storage, choice among open-source models, onchain settlement, and API access that does not rely too heavily on human gatekeepers. This is also why the platform appeals not only to ordinary users but also to AI agent applications, developers, and teams that want to embed AI services into existing products. For these participants, the value of Venice is not limited to whether it can generate a paragraph of text or an image. Its value lies in whether AI inference can function as a lower-friction, more predictable, and more durable infrastructure layer that can be integrated directly into applications.
How does VVV (Venice) work?
The operating logic of Venice can be understood across three layers, which are the product layer, the infrastructure layer, and the onchain settlement layer. At the product layer, users submit prompts through a web interface or application environment. Those prompts may involve text, images, code, or character-based interaction. These requests are not designed around long-term centralized storage. Instead, local preservation of conversation history is treated as the default direction. One of the key design priorities of Venice is to avoid storing prompts and responses on its own servers for long periods of time. In practice, prompt data is sent through encrypted channels and proxy services to external GPU providers for inference, and the output is then returned to the user’s device. This means Venice is not trying to become a large-scale data collection system. It is trying to operate as an inference network that holds as little data as possible and mainly coordinates the flow of requests and responses. That architecture directly shapes the nature of the product because it reassigns control over the most sensitive parts of the AI stack, including who can see content, who stores conversations, and who can reuse them. If a user clears local storage, past conversations may disappear as well. That is a direct trade-off between convenience and privacy.
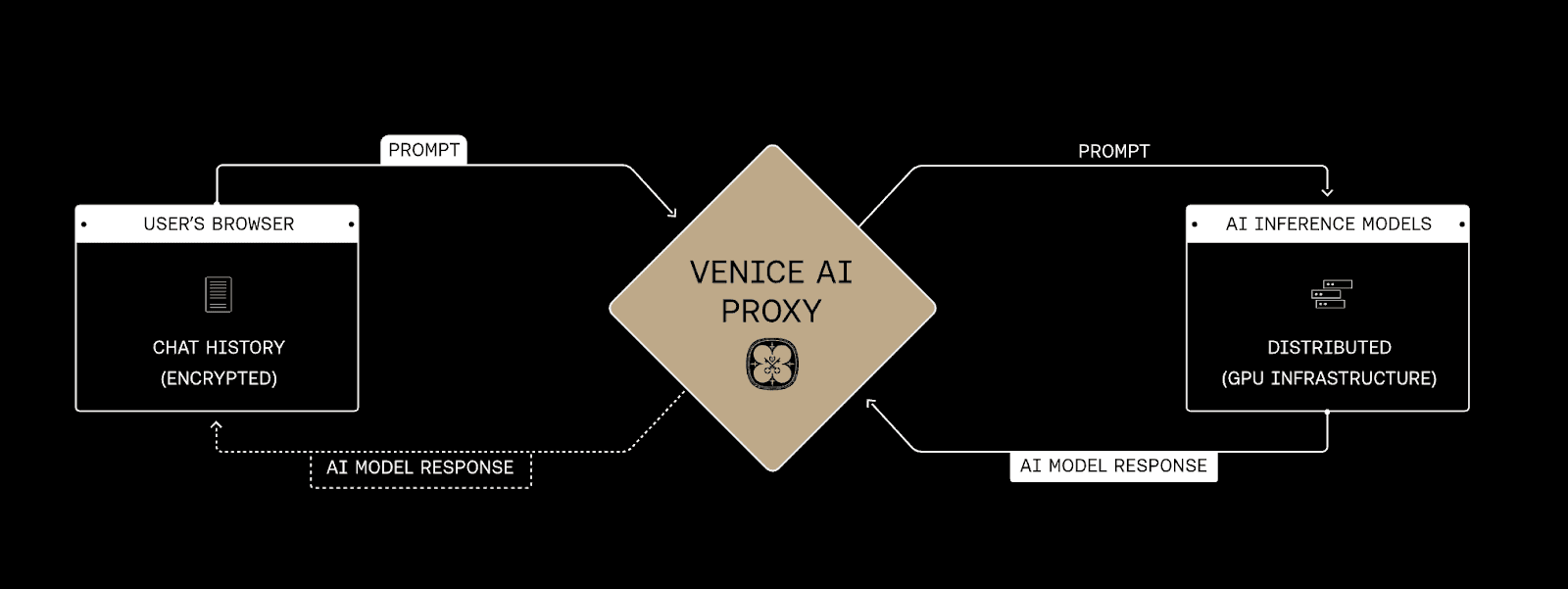
VVV Privacy Architecture, Source: https://venice.ai/about
At the model layer, Venice is built around a multi-model architecture that relies primarily on open-source weights. The product is not tied to a single model provider. Instead, Venice positions itself as a model aggregation and inference distribution platform. This matters because the platform’s competitive edge does not come only from model ownership. It also comes from model integration, routing efficiency, product experience, and privacy architecture. If a future open-source model performs better in code generation, image generation, or multimodal understanding, the Venice architecture can in theory continue to swap in and expand support for new models. That kind of replaceability and composability looks very similar to the modular infrastructure logic seen in blockchain ecosystems. It also makes Venice look more like an application-layer AI protocol than a traditional monolithic software company.
The most important difference between Venice and a typical AI platform is that Venice tries to turn inference access into something that can be obtained through token relationships rather than pure pay-per-use billing. By staking VVV, holders can gain a proportional share of Venice’s network-wide inference capacity. In earlier materials, that capacity is often described through Venice Compute Units, or VCUs, which standardize different forms of compute demand into a unified measurement framework. This changes the pricing logic of AI services. In the traditional model, users pay for each request and marginal cost rises with usage volume. Venice tries to change that relationship by having users first hold or stake a network asset, then receive access to inference resources based on their share. For ordinary users, that means high-frequency usage does not necessarily require repeated per-call payments. For developers and agent-based applications, it turns API access into something closer to a capitalized infrastructure right, which makes long-term cost planning more stable. That is also why VVV is not just a payment token. It is part of the product mechanism itself.
After Q2 of 2025, Venice pushed this model further in the direction of clearer compute assetization. With the introduction of DIEM, the platform no longer stopped at giving stakers a floating proportional share of API capacity through VVV alone. It started converting part of that usable compute into a more legible long-duration onchain credit unit. DIEM is described as a tradable ERC-20 asset that represents a fixed daily API allowance, and it is minted by locking already staked VVV. The point of this design is not simply to launch an additional token. The point is to convert AI usage rights from an abstract proportional entitlement into an onchain asset that developers can model more easily inside budgets, balance sheets, and operating plans. This shows that Venice is trying to push AI infrastructure toward a more DeFi-like asset logic, where compute is not only consumed, but can also be held, allocated, locked, traded, and priced.
VVV (Venice) market price & tokenomics
On the supply side, VVV launched with a nominal initial supply of 100 million tokens, but the circulating supply and effective total supply changed in important ways over time. The initial allocation included 50 % for community and related AI ecosystem airdrops, 35 % for the company, 10 % for incentives, and 5 % for liquidity development. Early distribution relied heavily on airdrops. That made VVV’s launch structure more community-led and user-led than capital-led by crypto market standards. This kind of setup can help build an early user base and generate strong attention quickly. It also means the secondary market can face heavier post-unlock pressure and sharper holder rotation once airdropped tokens start moving. That effect is even more pronounced in AI-related tokens, which are already highly sensitive to narrative rotation.
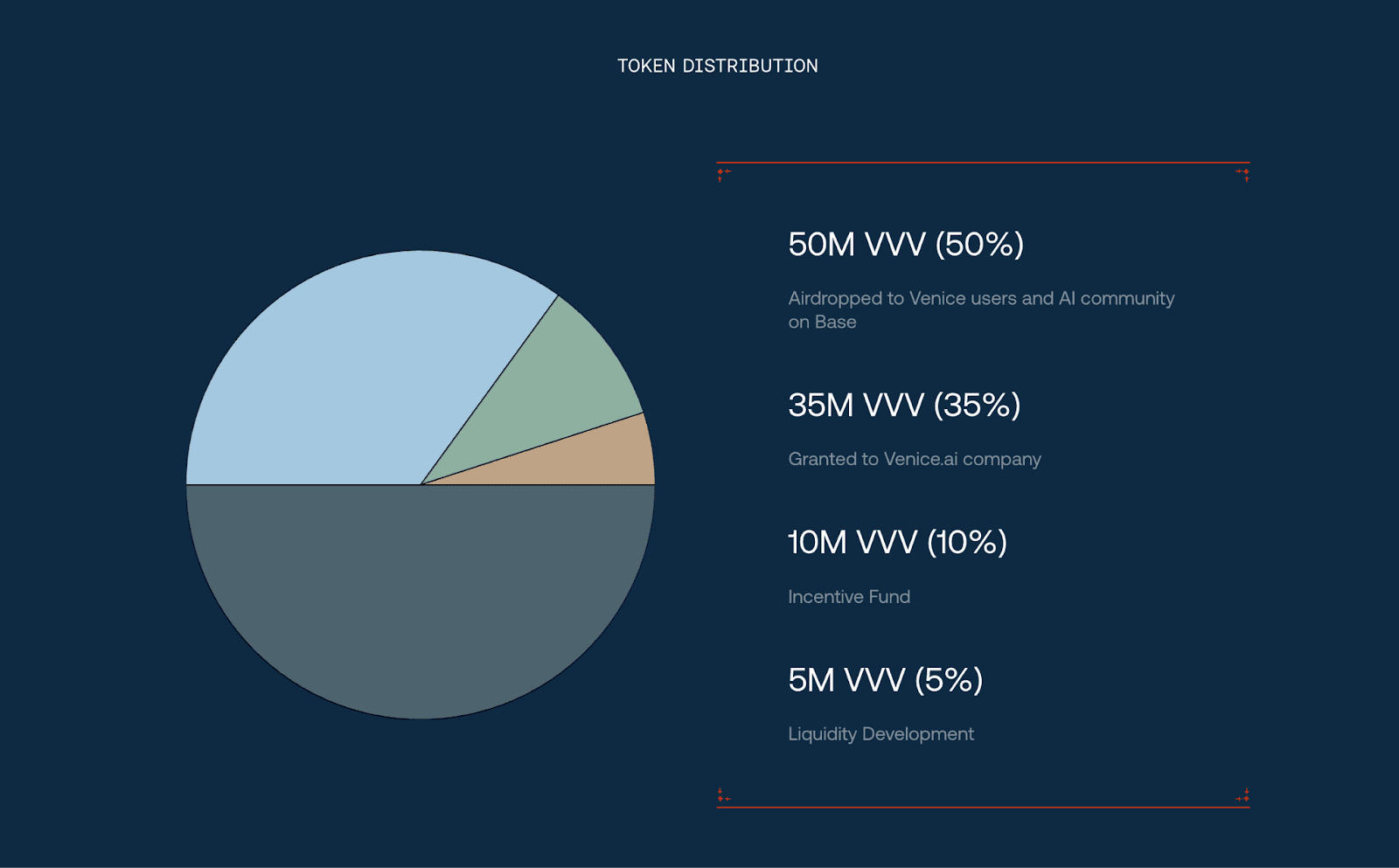
VVV token distribution, Source: https://venice.ai/vvv
VVV is the native token that links compute access, staking relationships, and onchain economic settlement inside the Venice ecosystem. It is not only a payment asset, and it is not merely a narrative token that signals community identity. It is designed as the core asset used to enter Venice’s inference allocation system. Users and developers can stake VVV to receive a share of Venice’s AI inference capacity. That share is sometimes described in the form of Venice Compute Units, or VCUs. Therefore, VVV is better understood as a foundational token that binds together AI access rights, compute allocation, and asset ownership. It is not simply a theme-driven token moved only by sentiment. Once a project shifts AI access from a subscription or pay-per-use model into a token staking model, the token stops being an external financing tool and becomes part of the service mechanism itself.
The burn mechanism is also a major part of VVV tokenomics. In March 2025, about 33.68 million unclaimed airdrop tokens were burned. That was an important supply-side turning point because it created a meaningful gap between the theoretical headline supply and the actual number of tokens that could potentially reach the market. Later, starting in October 2025, the platform began using part of its revenue to buy back and burn VVV. This tied platform revenue more directly to token scarcity. The significance of that design is that VVV’s value no longer depends only on staking and emissions. It also becomes increasingly linked to whether Venice can generate sustained commercial revenue from real product usage. If the user base and developer activity continue to grow, and if platform revenue increases with that growth, then buybacks and burns can create ongoing compression on liquid supply.
Why do you invest in VVV (Venice)?
The market continues to pay attention to VVV for reasons that go beyond it being just another AI-themed token. Venice sits at the intersection of three strong narratives in crypto. The first is privacy, because the platform is built around minimizing server-side data retention and keeping user interaction as local as possible. The second is censorship resistance, because Venice is positioned as an inference layer that gives users broader access to open-source models without relying on the content controls that define most mainstream AI platforms. The third is the direct connection between onchain assets and real product access, since VVV is not designed merely as a symbolic ecosystem token, but as a core asset tied to inference rights, compute allocation, and long-term usage within the network. Many AI projects remain largely narrative-driven and use tokens mainly as fundraising tools or branding devices. Venice takes a different route by trying to make the token participate directly in service allocation. That makes it easier to discuss VVV as a mechanism-driven asset rather than a simple AI concept coin. In crypto, privacy protection and user-controlled data relationships have been durable value propositions for a long time. When those values are applied to AI inference, Venice naturally becomes a project with cross-narrative appeal. It is not only talking about smarter models but also addressing who controls data, who defines the limits of acceptable output, and who owns long-duration access to compute. Those questions overlap closely with issues the crypto ecosystem has been debating for more than a decade.
Venice has also not limited itself to the role of a front-end chatbot. It has clearly expanded toward developer and AI agent use cases. The Venice API offers private inference access and is compatible with OpenAI-style API structures, which lowers switching costs and makes integration easier for existing applications. That matters because the real scaling vector for AI infrastructure is not a small number of heavy chatbot users. It is a broad set of embedded applications, autonomous agents, and enterprise workflows. If developers can lock in cost exposure through staking or through mechanisms such as DIEM, and if they can call models without heavily exposing user data, then Venice becomes more than an alternative chat product. It becomes a capability layer that can sit behind other applications. Traditional AI API costs are usually treated as operating expenses. The more demand grows, the higher the cost becomes, and pricing may shift with provider policy. Venice tries to use VVV and later DIEM to transform recurring AI usage costs into onchain assets that can be staked, locked, and incorporated into longer-term cost planning. It is not forcing blockchain finance onto an unrelated real-world product. It is identifying an industry with persistent cost pressure, which is AI inference, and then restructuring that pricing logic through digital asset design.
Is VVV (Venice) a good investment?
From a mechanism standpoint, the strength of VVV is that it is not loosely attached to the outside of the product. It participates directly in compute access and resource allocation across the Venice platform. As long as Venice’s private inference services, developer API, AI character interaction, and multi-model access continue to be used, VVV retains a real functional foundation. The materials you provided also show that the project later added more advanced mechanisms such as emission cuts, airdrop burns, revenue-funded buybacks, and DIEM. This suggests that the Venice team did not stop at launching a token. It continued adjusting the economic model in order to create a tighter relationship between product usage, platform revenue, and token value.
At the same time, the AI services market is intensely competitive. Open-source models are improving quickly. Major centralized platforms continue to reduce pricing, expand product capability, and improve their own privacy features. That means Venice does have meaningful differentiation through privacy and lower-censorship design, but it still needs to prove that this differentiation can turn into durable commercial strength over time. For that reason, the research value of VVV does not depend simply on whether AI is a hot sector. The deeper question is whether Venice can sustain real demand for private and low-censorship AI access rather than relying on short-term narrative traffic. Another key question is whether VVV remains an irreplaceable asset for accessing core services and compute rights, instead of being diluted by subscription alternatives or centralized substitutes. It is also necessary to examine whether platform revenue, buybacks, burns, staking, and DIEM can actually form a clear, transparent, and durable value capture loop. Research on VVV should not stop at price volatility. It should continue to track whether product adoption, onchain structure, and token mechanics are truly reinforcing one another.
Explore the latest VVV (Venice) price and live chart, trade VVV on FameEX, and access real-time market data! Get started now with a seamless trading experience!
Disclaimer: The information provided in this article is intended only for educational and reference purposes and should not be considered investment advice. Conduct your own research and seek advice from a professional financial advisor before making any investment decisions. FameEX is not liable for any direct or indirect losses incurred from the use of or reliance on the information in this article.